
RAG: odpowiedzi prosto z Twoich danych
budujemy przewagę w erze AI
Tworzymy rozwiązania, które łączą wyszukiwanie w dokumentach z generowaniem odpowiedzi. Krócej szukasz — szybciej pracujesz.
Wdrażamy RAG dla firm: system, który przed odpowiedzią przeszukuje Twoje pliki, wiki i bazy, a potem składa z nich jasną odpowiedź z cytatami. Dzięki temu ludzie szybciej znajdują konkrety, a Ty masz pewność pochodzenia treści. Obsługujemy polski i angielski, działamy on-prem lub w chmurze zgodnej z RODO, dziedziczymy uprawnienia (SSO/LDAP/Okta), integrujemy się ze Slack/Teams, Confluence i SharePoint.
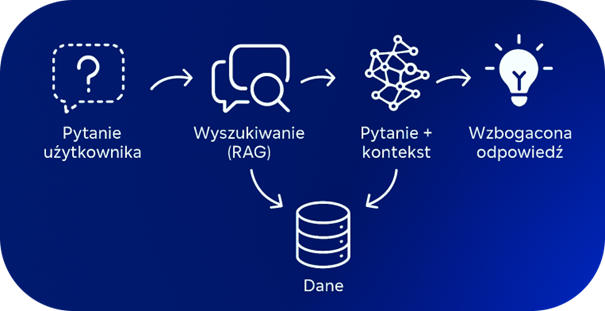
Czym jest RAG (Retrieval-Augmented Generation)?
RAG to sposób budowania rozwiązań na modelach językowych, w którym najpierw szukamy wiedzy w Twoich dokumentach (np. przy pomocy bazy wektorowej), a dopiero potem model tworzy odpowiedź.
Dzięki temu odpowiedzi są:
- trafniejsze – wspierają się realnymi danymi,
- aktualne – korzystają z najnowszych wersji dokumentów,
- weryfikowalne – zawsze z linkami/cytatami
Kluczowe korzyści z wdrożenia rozwiązania RAG

Mniej szukania, więcej pracy merytorycznej
odpowiedzi w sekundach, bez przeklikiwania folderów.

Aktualność
rozwiązania RAG korzystają zawsze najnowszych wersji dokumentów.

Pewność i ślady źródeł
każda odpowiedź ma wskazane dokumenty, sekcje i strony.

Bezpieczne przetwarzanie danych
przetwarzamy lokalnie lub w wybranej chmurze zgodnej z RODO.
Dla kogo i do czego

- Wewnętrzna baza wiedzy – procedury, polityki, regulaminy, instrukcje.
- Obsługa klienta – szybkie odpowiedzi na zgłoszenia, cytaty z umów i warunków.
- Sprzedaż i presales – specyfikacje, porównania, warunki ofert, RFI/RFP.
- Compliance i prawo – wyszukiwanie zapisów w umowach i regulacjach z cytatami.
- Operacje i IT – runbooki, dokumentacja systemowa, logi, zmiany.
- HR i finanse – odpowiedzi o świadczeniach, rozliczeniach, wnioskach.
Przykładowe funkcje, które możemy zaimplementować
- Cytowane źródła w odpowiedzi (link, nazwa dokumentu, numer strony/sekcji).
- Uprawnienia i widoczność – zgodnie z Twoim SSO/LDAP/Okta.
- Tryb „tylko na podstawie dokumentów” – bez dopowiedzeń z „pamięci” modelu.
- Progi pewności i komunikaty o brakach – gdy materiału nie ma lub jest niejednoznaczny.
- Panel jakości – frazy, które wpisują użytkownicy, hit rate, ocena odpowiedzi.
- Języki – polski/angielski (inne na życzenie).
- Integracje – Slack/Teams, widget w przeglądarce, e-mail, API, Confluence/SharePoint, bazy wiedzy.
- Obsługiwane formaty – PDF (tekstowe, skany po OCR), DOCX, XLSX/CSV, PPTX, strony WWW i inne.
Dlaczego RAG wygrywa z „czystym” modelem językowym?
Klasyczne LLM-y odpowiadają na podstawie tego, co zapamiętały w czasie treningu. Ich wiedza szybko się starzeje i nie obejmuje nowych materiałów. RAG łączy generowanie odpowiedzi z bieżącym wyszukiwaniem w Twoich źródłach (pliki, wiki, bazy). Dzięki temu dostajesz odpowiedzi oparte na aktualnych, sprawdzonych dokumentach, z podanymi źródłami. To też ogranicza „halucynacje” — model nie dopowiada z pamięci, tylko korzysta z realnych treści w momencie tworzenia odpowiedzi.
![Schemat porównawczy: Zwykły LLM (głowa i sieć neuronowa, strzałka w dół, cylindryczna baza danych, dymek z odpowiedzią) kontra RAG (głowa i sieć neuronowa, strzałka w dół, dokument i baza danych, dymek z odpowiedzią z cytatami [1], [2], [3]). Ilustruje, że RAG zapewnia odpowiedzi z podanymi źródłami.](https://sysmo.pl/wp-content/uploads/2025/11/Obraz7-5.png)
Strategie wdrażania RAG w firmie
1. Wybór przypadków użycia
Najpierw należy wskazać obszary o największym zwrocie:
- wsparcie decyzji (porównania, warunki, procedury).
- obsługa klienta i helpdesk,
- tworzenie raportów i analiz z dokumentów,
- rekomendacje ofert i produktów,
2. Przygotowanie danych
Jakość źródeł przesądza o jakości odpowiedzi:
- audyt treści i porządkowanie (duplikaty, stare wersje),
- proste standardy: struktura, tagi, nazewnictwo,
- stałe odświeżanie i kontrola poprawności według harmonogramu.
3. Rozwój iteracyjny
Zalecane jest podejście krok po kroku:
- start w ograniczonym obszarze (pilotaż),
- systematyczne zbieranie opinii użytkowników,
- strojenie wyszukiwania, progów pewności i trybu „tylko z dokumentów”.
4. Zgodność i etyka
Bezpieczeństwo i przejrzystość powinny być wbudowane:
- ochrona prywatności, szyfrowanie, kontrola dostępu (np. SSO/LDAP),
- jasne zasady korzystania z AI w organizacji,
- regularne audyty: błędy, uprzedzenia, logi i retencja danych.

FAQ – najczęściej zadawane pytania o RAG
Co to jest RAG?
Podejście, w którym system najpierw wyszukuje fragmenty z Twoich dokumentów, a potem tworzy odpowiedź na ich podstawie. Dzięki temu dostajesz rzeczowe, aktualne odpowiedzi z odwołaniami do źródeł.
Kiedy RAG ma sens?
Gdy masz sporo materiałów (procedury, oferty, wiki, regulaminy) i chcesz, by ludzie szybko znajdowali konkret. Sprawdza się w obsłudze klienta, sprzedaży, wewnętrznej bazie wiedzy, compliance i nie tylko.
Czym RAG różni się od „chatbota”?
Nie opiera się na sztywnych regułach ani wiedzy ogólnej. Wyszukuje treści w Twoich plikach i buduje odpowiedź ze wskazaniem źródeł oraz z poszanowaniem uprawnień.
RAG czy fine-tuning?
Często oba. RAG daje aktualność i ścieżkę źródeł. Fine-tuning pomaga z tonem, terminologią i krótkimi poleceniami specyficznymi dla firmy.
Jakie formaty danych obsługujecie?
PDF (tekstowe; skany po OCR), DOCX, XLSX/CSV, PPTX, strony WWW, Confluence/SharePoint, bazy wiedzy i inne.
Co z uprawnieniami do dokumentów?
System widzi tylko to, do czego użytkownik ma dostęp (SSO/LDAP/Okta). Reguły dziedziczymy z systemów źródłowych.
Czy odpowiedzi mają źródła?
Tak. W odpowiedzi podajemy nazwę dokumentu, sekcję/stronę i link.
Jak ograniczacie „zmyślanie”?
Tryb „tylko na podstawie dokumentów”, filtry treści, progi pewności oraz jasny komunikat, gdy brakuje materiału.
Jak często odświeżane są dane?
Ustalamy harmonogram — od ręcznego odświeżania po ciągłą synchronizację (np. co godzinę). Po zmianie treści system korzysta z nowej wersji.
Jakie są opcje modeli?
Możemy użyć modeli w chmurze lub rozwiązań zarządzanych lokalnie. Dobór zależy od wymagań bezpieczeństwa, kosztów i języków.
Skorzystaj z darmowej analizy Twojej firmy


